

Ijraset Journal For Research in Applied Science and Engineering Technology
Sounding Sentiments: A Cognitive AI Approach to Speaker-Linked Emotion Analysis
Authors: Dr. Seema Singh, Gungun Tyagi, Kumar Divij, Amitesh Maity, Annu Redhu, Srishti
DOI Link: https://doi.org/10.22214/ijraset.2024.58631
Certificate: View Certificate
Abstract
Over the past few decades, there has been significant progress in sentiment analysis, primarily focusing on analyzing text. However, the field of sentiment analysis linked to audio remains relatively undeveloped in the scientific community. This study aims to address this gap by introducing sentiment analysis applied to voice transcripts, specifically focusing on distinguishing emotions of individual speakers in conversations. The proposed research article seeks to develop a sentiment analysis system capable of rapidly interacting with multiple users and analyzing the sentiment of each user\'s audio input. Key components of this approach include speech recognition, Mel-frequency cepstral coefficients (MFCC), dynamic time warping (DTW), sentiment analysis, and speaker recognition.
Introduction
I. INTRODUCTION
Sentiment analysis is used to analyze people's feelings or attitudes based on a conversation, topic, or general conversation. Sentiment analysis is used for various purposes such as in various applications and websites. We use our knowledge to create an assistant that understands and learns the human way of thinking based on holding each other. A machine that understands people's emotions/moods through these conversations and what keyword was used in the conversations. The combined sentiment analysis of the speaker and the speech is done with data and conversations extracted from previous conversations and various processes.
Understanding people's thoughts and feelings has many applications. For example, technology that can understand and respond to a person's personal emotions will be important. Imagine a device that senses a person's mood and adjusts its settings based on the user's preferences and needs. Such innovations can improve user experience and satisfaction. In addition, research institutions are actively working to improve the quality and translation of audio content into text. This includes a variety of materials such as news reports, political speeches, social media, and music. By enabling this technology, they aim to make audio content more accessible and useful in many situations.
Our research body has also worked on voice evaluation research [1,2,3] to study the conversation between the user and the assistance model and distinguish between each speaker and their emotions. Because there are several speakers in a conversation, it is difficult to analyze the text data of the recorded voice, so this paper proposes a model that can easily recognize the presence of different speakers and identify them as separate, and perform voice analysis; individuals speak and responds according to his feelings.
We present an approach and viewpoint on investigating the hurdles and techniques involved in audio perception analysis of sound recordings through speech recognition. Our methodology utilizes a speech recognition model to interpret audio recordings, coupled with a suggested method for user discrimination based on a predetermined hypothesis to authenticate distinct speakers. Subsequently, each segment of speech data is scrutinized, enabling the system to accurately discern genuine emotions and topics of conversation.
Part II, we delve into the underlying hypothesis regarding the speaker, explore speech recognition, and delve into sentiment analysis. Section III elaborates on the proposed system, while Section IV outlines the characteristics of the experimental configuration. Following that, Section V showcases the results obtained and provides an extensive analysis. Finally, Episode VI concludes the project.
II. LITERATURE REVIEW AND CONTEXT
A. Sentiment Analysis
This method, also known as Sentiment Analysis SA, the objective is to ascertain whether a document conveys positive or negative sentiment through the analysis of sentiments expressed in textual form. Various techniques are employed in sentiment analysis research, including maximum entropy, decision trees, Naïve Bayesian, and support vector machines.
Mostafa et al. [4] classify sentences in each text as subjective or objective, subsequently processing the subjective portions using standard machine learning techniques to enable the polarity classifier to disregard false or irrelevant terms. Gathering and classifying data obtained from the analysis at the sentence level is time-consuming, and testing this process poses challenges. For hypothesis testing we use the following: Naive Bayes, Linear Support Vector Machines and VADER [6]. We compare these methods to determine the best-performing algorithm for our preferred use.

2. Feature Matching
Dynamic time Wrapping (DTW)--- DTW is a rule that is understood as a technique of dynamic programming by Stan Republic of El Salvador et al. [7]. This rule is used to measure the similarity between two statistics that change corresponding to speed or time. If the series is "warped" non-linearly—that is, made tensile or shrunk on its time axis—just once, this system is also likely to detect the optimal alignment between the days' worth of data. Then, by using this warp between given two statistics, one can observe resemblance or complimenting areas between those two statistics. DTW's basic idea is to find two major dynamic patterns that possess similarities with one other and then imply a least possible distance amid them.
Ultimately, the statistic is encapsulated by employing various computational methods for measuring distance or similarity, such as geometric distance, Canberra Distance, and Correlation. A thorough comparison of these methods is presented in the results section of the paper.
III. PROPOSED SYSTEM
In our research, we are typically suggesting a model to analyze sentiments that makes the use of alternatives picked from the signals of speech provided to comprehend the emotion that speaker feels at the time when the phrase is spoken. There are four steps in the method: 1) VAD-equipped pre-treatment; 2) Speech Recognition; 3) Speaker Identification; and 4) Sentiment Analysis.
There is a system that detects the voice activity by receiving the signals. Later it uses these to identify and distinguish the phrase sounds from the signals received. These sounds are stored as chunks of information, which are subsequently transferred to the system for recognition of speech and speaker discrimination so as to identify the speaker's identity and content. The recognition system of speaker labels the segments with the IDs of speakers. It is relevant to mention that this system operates autonomously, identifying if the segments belong to the same speaker or two different speakers and labeling them as such. These segments are then transformed to text by the technology of speech recognition. In addition, the algorithm compares the transcribed text with the Speaker Id. It continues like a conversation inside the data. The textual output generated by a speaker-exclusive speech recognition system holds the potential to estimate the sentiment emphasized by the speaker at the moment of recording the statement. The whole method is expressed pictorially in the Figure 2.
IV. EXPERIMENTAL CONFIGURATION
A. Data set
Twenty-one audio files that were recorded in highly regulated environments make up our dataset [10]. Three distinct scripts are utilized for oral communication between two individuals. In these recordings, seven speakers—four men and three women—are fully engaged. The chats were labeled as per the current scenario. The audio has been recorded in form of mono-tracks for an approximation of ten seconds, with a 16 KHz sample rate.
A sample of dataset is displayed in Figure 3.

Conclusion
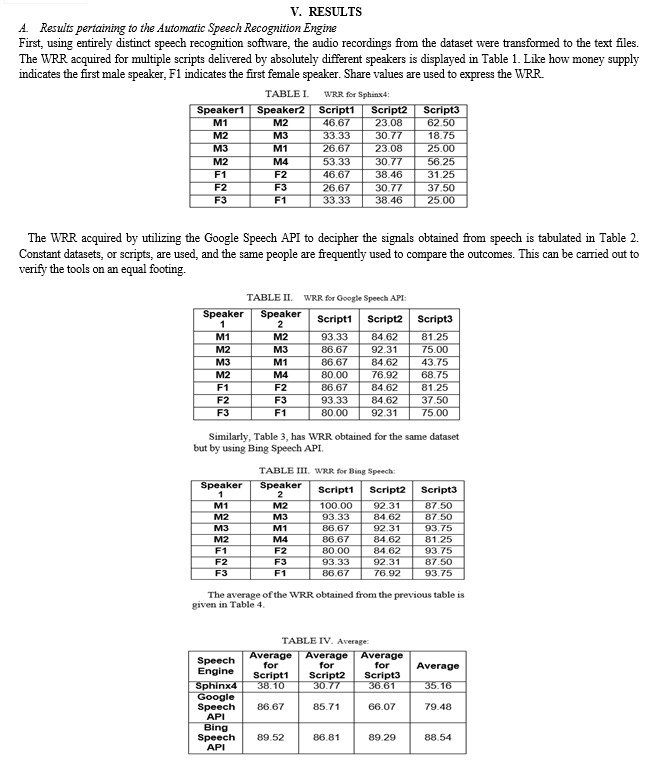
This research paper coins a generalized model that takes in use the audio file from two speakers as an input, mechanically converts the audio to text, later, plays back speaker identification so as to study the identities of the speaker and the content provided. We have designed an easy to use system that attempts to do the precursory task in the duration of this study. The system functions effectively with artificially generated datasets; however, we tend to perform better when grouping larger datasets to improve the system\'s measurability. Even though the system accurately interprets the sentiments of the speakers in casual dialogue, it has certain shortcomings. Firstly, it is unable to distinguish between two speakers speaking at the same time. Only one speaker should speak at a time during a speech. In the future, we would seek to solve these issues and enhance the system\'s measurability and accuracy.
References
[1] Pang, B., & Lee, L. (2004, July). Sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In Proceedings of the 42nd annual meeting on Association for Computational Linguistics (p. 271). Association for Computational Linguistics. [2] Pang, B., & Lee, L. (2005, June). Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. In Proceedings of the 43rd annual meeting on association for computational linguistics (pp. 115-124). Association for Computational Linguistics. [3] Pang, B., Lee, L., & Vaithyanathan, S. (2002, July). Thumbs up?: sentiment classification using machine learning techniques. In Proceedings of the ACL-02 conference on Empirical methods in natural language processing-Volume 10 (pp. 79-86). Association for Computational Linguistics. [4] Shaikh, M., Prendinger, H., & Mitsuru, I. (2007). Assessing sentiment of text by semantic dependency and contextual valence analysis. Affective Computing and Intelligent Interaction, 191- 202. [5] Walker, W., Lamere, P., Kwok, P., Raj, B., Singh, R., Gouvea, E., ... & Woelfel, J. (2004). Sphinx-4: A flexible open source framework for speech recognition. [6] Tang, D., Wei, F., Yang, N., Zhou, M., Liu, T., & Qin, B. (2014). Learning Sentiment-Specific Word Embedding for Twitter Sentiment Classification. [7] Maas, A. L., Daly, R. E., Pham, P. T., Huang, D., Ng, A. Y., & Potts, C. (2011). Learning Word Vectors for Sentiment Analysis. [8] Dos Santos, C., & Gatti, M. (2014). Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts. [9] Socher, R., Perelygin, A., Wu, J. Y., Chuang, J., Manning, C. D., Ng, A. Y., & Potts, C. (2013). Recursive deep models for semantic compositionality over a sentiment treebank. Proceedings of the conference on empirical methods in natural language processing (EMNLP), 1631-1642. [10] Kim, Y. (2014). Convolutional neural networks for sentence classification. arXiv preprint arXiv:1408.5882. [11] Xia, R., & Zong, C. (2011). Ensemble of feature sets and classification algorithms for sentiment classification. [12] Zhang, Y., & Wallace, B. C. (2015). A Sensitivity Analysis of (and Practitioners\' Guide to) Convolutional Neural Networks for Sentence Classification. [13] Poria, S., Cambria, E., & Gelbukh, A. (2016). Aspect extraction for opinion mining with a deep convolutional neural network. [14] Wang, P., Xu, J., Xu, B., Liu, C., Zhang, H., & Wang, F. (2012). Sentiment Analysis on Twitter with Semi-supervised Learning. [15] Severyn, A., & Moschitti, A. (2015). Twitter Sentiment Analysis with Deep Convolutional Neural Networks. [16] Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to Information Retrieval. Cambridge University Press. [17] Bird, S., Klein, E., & Loper, E. (2009). Natural Language Processing with Python. O\'Reilly Media [18] Towards Data Science - A Gentle Introduction to Sentiment Analysis [19] Analytics Vidhya - Text Mining and Sentiment Analysis: A Beginner\'s Guide [20] Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving Language Understanding by Generative Pretraining. [21] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is All You Need. [22] Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., & Zettlemoyer, L. (2020). BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Understanding. [23] Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., ... & Brew, J. (2019). Hugging Face\'s Transformers: State-of-the-art Natural Language Processing [24] Dathathri, R., Madotto, A., Lan, Z., Ni, J., Dong, L., & Gao, J. (2020). Plug and Play Language Models: A Simple Approach to Controlled Text Generation. [25] Shao, L., Feng, X., Wallace, B., & Bengio, Y. (2017). Generating high-quality and informative conversation responses with sequence-to-sequence models [26] Serban, I. V., Sordoni, A., Lowe, R., Charlin, L., Pineau, J., Courville, A., & Bengio, Y. (2016). A hierarchical latent variable encoder-decoder model for generating dialogues. [27] Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., ... & Liu, P. J. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. [28] Brown, T. B., Mané, D., Roy, A., Abolafia, D. A., & others. (2020). Language Models are Few-Shot Learners. [29] Mikolov, T., Sutskever, I., Chen, K., Corrado, G., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. [30] Li, J., Monroe, W., Ritter, A., Galley, M., Gao, J., & Jurafsky, D. (2016). Deep Reinforcement Learning for Dialogue Generation. [31] Serban, I. V., Sordoni, A., Bengio, Y., Courville, A., & Pineau, J. (2017). A hierarchical latent variable encoder-decoder model for generating dialogues. [32] Zhang, S., & Xu, W. (2017). Neural Network-based Abstract Generation for Opinions and Arguments. [33] Kannan, A., Kurach, K., Ravi, S., & Bengio, Y. (2016). Adversarial Training for Text-to-Image Synthesis. [34] Zhang, Z., & Lapata, M. (2014). Chinese whispers: An efficient graph clustering algorithm and its application to natural language processing problems.
Copyright
Copyright © 2024 Dr. Seema Singh, Gungun Tyagi, Kumar Divij, Amitesh Maity, Annu Redhu, Srishti . This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET58631
Publish Date : 2024-02-27
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online